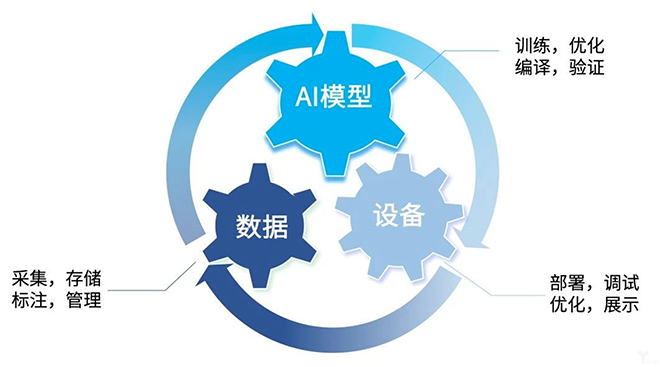
在AI模型训练领域,数据语料库被誉为新时代的“石油”。特别是对于AI模型(如GPT、BERT等)的训练,高质量的语料库至关重要。数据语料库的下载数量、质量和多样性直接影响模型的性能和泛化能力。
AI模型训练语料库是构建和优化AI模型的基石,大模型常使用文本图片视频等公共语料库混合体作为预训练语料库。
正聚公司是一家有科研背景、以技术发展为导向的
AI基础数据服务企业,为数家人工智能从业公司和高校科研机构提供
AI模型语料采集、数据标注、
语料库产品等数据服务。同时正聚公司配备丰富的语料库,包含但不限于社交礼仪语料库、法律与政府文件语料库、人文历史语料库、期刊文献语料库。可简化数据采集流程,助力AI模型训练。
通过正聚的
AI模型语料库采集解决方案,助力AI模型训练获取精准市场数据资料,可克服地域和语言障碍,并应对反爬虫挑战,全面提升市场研究、竞争分析和业务决策的效率与成功率。
 【正聚技术优势】
【正聚技术优势】
高匿IP池:全网独有IP轮换策略,模拟真人操作,有效规避目标网站的反爬机制。
自动去重过滤:提供去重、分辨率过滤、标签匹配等预处理功能,输出即用高质量训练语料库。
多模态兼容:文本、视频、图像一网打尽,AI训练大模型要啥就给啥。

 :385498515
:385498515